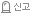
출력해라(“이거”);
화면에 뭘 출력하라는 것도 함수가 담당하는데, 이에 해당하는 함수는 printf이다. f를 빼먹지 말자. printf는 인자를 받아서 그것을 화면으로 출력해 준다. 따라서, 다음과 같이 쓰면 된다.
printf(“this”);
이렇게 하면 출력 결과는 다음과 같다.
this
쉽다.
하지만, 이것만으로는 내가 계산한 결과를 출력하는데 너무나 부족함이 많다. 가령, a+b를 계산해서 c=a+b라고 정해놨는데, c를 그냥 c라고 안에 넣어서
printf(“result is c”);
라고 쓴다면, 그 결과는
result is c
가 된다. 난 이런걸 원한게 아니다. 당신도 아마 원하지 않았을 것이다. 우린 a=10, b=20을 넣으면 result is 30이 되길 원하고, a=20, b=40을 넣으면 result is 60이 되길 원한다. 그렇다면, 다음의 형식을 따라해라.
printf(“result is %d”,c);
이렇게 하면 %d가 있는 자리에 c에 해당하는 값이 들어가서 출력된다. 응용하면 다음과 같은 것도 된다.
printf(“%d plus %d is %d”,a,b,c);
어떻게 쓰는지 감이 올 것이다. 뭔가 대입해야 하는 자리에 무조건 %d를 써 놓고, 대입할 순서대로 변수 이름을 적어주면 되는 것이다.
문제는, %d는 정수 출력에만 쓸 수 있다는 것이다. 따라서, 정수가 아닌 다른 변수를 출력할 때는 그에 맞는 변수를 적어줘야 한다.
%d 정수를 10진수로 출력
%o 정수를 8진수로 출력
%x 정수를 16진수로 출력
%u 정수를 부호없는 10진수로 출력
%c 정수를 문자로 출력(char 형 출력할때 사용)
%s 포인터나 배열 출력할때 사용
%f 실수를 소숫점 형식으로 출력 (xxx.xxx형식)
%e 실수를 과학적 표현식으로 출력 (xxx+Eyyy 형식. 이건 xxx*10^yyy를 뜻한다)
%g %e나 %f중에 문자수가 적은쪽으로 출력
그리고 주의사항, % 자체를 출력하려면 %%라고 써야 한다.
아무튼, 이대로만 적으면 변수에 적혀있는게 전부 출력된다. 그럼, 이걸 원하는대로 출력하라고 시킬 수도 있다. 가령, 소숫점 위로는 3자리를 출력하고, 소숫점 아래로 5자리까지 출력하는, 즉 xxx.xxxxx형식을 윈한다면, %와 f사이에 3.5를 쓰면 된다.
기본적으로 출력은 오른쪽에 붙어서 나오지만, 만약 왼쪽부터 출력을 시키고 싶으면 %다음에 -를 붙이면 된다. 즉 %-3.5f는 실수를 왼쪽에서 붙여서 3자리.5자리 형식으로 출력하라는 뜻이 된다. 만약 f앞에 l을 붙이면, long형식을 출력할때 사용한다. 즉, long double 이나 long int를 출력할때 lf나 ld를 사용하면 된다.
여전히 출력상의 문제는 발생한다. 왜? 위와 같이 하면 모든 출력물이 한줄에 붙어서 나오기 때문이다. 가령 a=10, b=20이라고 하고, 다음을 실행하면 어떻게 될까?
printf(“%d%d”,a,b);
그럼 출력은
1020
이 된다. 그렇다고, 구분을 짓겠다고
printf(“%d %d”,a,b);
와 같은 형식을 넣는것도 문제다. 왜? 한줄 넘길 수가 없으니까. 즉,
10
20
형식으로 출력을 시키는 건 못한다는 거다. 어떻게 해야 할까? 다음과 같이 하자
printf(“%d \n %d”,a,b);
이렇게 하면 \n이 그 다음에 오는 문장을 한줄 아래로 보내주게 된다.
여기에 \n만 쓸 수 있는건 아니다. \을 붙여서 쓰는 글자들을 Escape문자열이라고 하는데
\n 한줄 넘기기(새로운 줄 시작)
\t TAB띄우기
\b 백스페이스
\r 그 줄 처음
\f 다음페이지로 넘어가기
\\ 백슬래시기호 그 자체 \
\’ 이건 ‘이다
\” 이건 “이다
따옴표는 printf등에서 안에 들어가는 내용과 밖에 변수 지정하는 부분을 구별하기 위해서 사용하기 때문에, 특별히 따옴표를 출력하려면 \을 붙여줘야만 한다는 것을 기억하자.